5 Screaming Frog Tipps, die jeder SEO kennen sollte
Der SEO-Spider Screaming Frog ist DAS liebste SEO-Spielzeug für alle, die noch an die zentrale Bedeutung von Onpage-SEO glauben! Aus den guten Agenturen ist er mittlerweile nicht mehr wegzudenken. Seine Einsatzmöglichkeiten sind vielseitig und wenn man weiß womit man arbeitet, nahezu grenzenlos. Jeder der ihn nutzt, weiß, dass man mit ihm schnell und einfach Titel-Duplikate, doppelte oder fehlende H1-Tags, Hreflang-Tag-Errors und Canonical-Fehler aufdecken kann. Doch das ist bei weitem nicht alles! Der schreiende Frosch birgt noch mehr Geheimnisse.

1. Wissen, wo der Frosch die Locken hat – Reports und Bulk Export
Jeder weiß, wie man mit dem Screaming Frog schnell und einfach Titel-Duplikate oder 404-Fehler finden kann. Die meisten wissen ebenfalls, dass sich die Ergebnisse des Crawlings bequem in .csv oder .xls Formate exportieren lassen:

Im weiteren Arbeitsschritt mit Excel weiterzuarbeiten hat viele Vorteile: Filter it, sort it, export it, send it. Allerdings fehlt hier die tierisch starke [pun intended] Funktion des Screaming Frog, die Inlinks zu URLs aufzulisten. Wie bekommt man also einen übersichtlichen Bericht über alle 404-Seiten samt Inlinks?
Alle Inlinks zu 404-Fehlern auf einen Blick und noch viel mehr
Im Hauptmenü unter „Bulk Export“ wählt ihr unter „Response Codes“ den Bericht „Client Error (4xx) Inlinks„. Hier hat der Frosch die Locken! Was ihr bekommt ist ein Bericht über alle Inlinks zu allen URLs der gecrawlten Domain im .csv oder .xls-Format. Und zwar samt Ankertexten. Eine weitere Möglichkeit ist in Excel den Bulk Export „All Inlinks“ nach dem Statuscode 404 zu filtern und voilà – Alle Inlinks zu 404-Fehlern auf einen Blick.
Folgende Exporte aus dem Feld „Reports“ möchte ich euch ebenfalls ans Herz legen:
- Redirect Chains: Deckt alle Weiterleitungsketten auf (z.B. http-Ketten) – perfekte Grundlage zur Linkjuice-Optimierung.
- Crawl Overview: Gibt euch die gesamten Crawl-Ergebnisse aus dem rechten Overview-Fenster als .csv/.xls – gut als Datengrundlage für Analysen.
- Canonicals: Spuckt auf einen Blick alle Canonical-Fehler der gecrawlten Domain aus – super Überblick zur Vermeidung grober Fehler.
- Insecure Content: Zeigt alle Ressourcen und Linkziele, die noch über http laufen – Ideal zur Kontrolle vom Relaunch.
2. Interne Verlinkung, Linktiefe & Responsetimes analysieren
Screaming Frog eignet sich ebenfalls perfekt für die technischen Analyse einer Domain. Im rechten Seitenfenster ist standardmäßig der Reiter Overview geöffnet. Dahinter finden sich die Reiter „Site Structure“ und „Response Times„.
Site Structure:
Hier finden sich nützliche Informationen zur internen Verlinkung und Webseitenstruktur. Im oberen Bereich des Fensters finden sich die 20 am stärksten intern verlinkten Seiten der Domain. Diese Statistik kann dabei helfen, Ansatzpunkte für die Optimierung der internen Verlinkung zu liefern. Darunter befindet sich das Fenster zur Linktiefe in Daten und visualisierter Form:
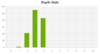
Eine Linktiefe von 0 entspricht der Startseite und URLs mit einer Linktiefe von 1 liegen in der Kategorie darunter. Dementsprechend wäre eine URL mit dem Wert 2 von der Form: www.gespidertedomain.de/kategorie/url. Diese Analyse kann dabei helfen entweder die gesamte Webseitenstruktur besser zu verstehen, oder aber sehr tief in der Struktur verborgene Seiten zu identfizieren, die für den Crawler schwer erreichbar sind (Stichwort Crawlbudget). Um eine Liste der sehr tief liegenenden URLs zu erhalten, einfach alle internen HTML-Elemente exportieren und in Excel nach „Level“ sortieren/filtern.
Response Times:
Im Reiter Response Times findet sich eine Auswertung der Serverantwortzeiten der gecrawlten URLs:
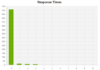
Das kann ziemlich pratkisch sein um die generelle Antwortzeit des Servers zu analysieren, oder schwarze Schafe zu identifizieren, die extrem lange response times aufweisen. Um eine Liste der URLs mit langen Antwortzeiten zu erhalten, einfach alle internen HTML-Elemente exportieren und in Excel nach „Response Time“ sortieren/filtern.
Mit dem „Bulk Export“ Report „All Inlinks“ bekommt ihr nicht nur detailgenau alle Inlinks zu Problemfällen – Der Bericht kann auch wunderbar dazu genutzt werden, die interne Verlinkung genau zu analysieren. Möglichkeiten sind hier bspw. bei den Linkzielen nach bestimmten URLs zu filtern und dann die Menge der Inlinks zu analysieren.
Ähnlich mächtig ist der Report „Bulk Export > All Anchor Text„. Dieser Bericht gibt einen super Überblick über alle verwendeten Ankertexte und entfaltet seine wahre Kraft durch Filtern der Daten.
3. Domain internem Duplicate Content ein Ende machen
Der Frosch hat eine zuverlässige Art und Weise Duplicate Content aufzuspüren – selbst auf großen Domains. Das funktioniert über übereinstimmende Hash-Werte. Einfach im Bericht „Internal > HTML“ alle URLs zu HTML-Dokumenten exportieren. Anschließend in Excel in der Spalte „Hash“ doppelte Werte farbig markieren lassen. In Excel findet ihr diese Funktion im „Start„-Tab unter „Bedingte Formatierung > Regeln zum Hervorheben von Zellen > Doppelte Werte„. Im Bereich zum Filtern von Daten könnt ihr nun ebenfalls nach der Zellenfarbe sortieren („Filter > nach Farbe filtern„). Wenn hier URLs mit noindex, Canonical oder Parametern die Relevanz der Ergebnisse schmälern, können diese einfach zuvor in Excel herausgefiltert, oder vor dem Spidern selbst vom Crawling ausgeschlossen werden.
4. URL-Listen und Sitemaps crawlen – mit dem „List Mode“
Der Screaming Frog verfügt nicht nur über die typische Spider-Funktion. Unter dem Menüpunkt „Mode“ im Hauptmenü finden sich die drei Modi:
- Spider: Crawlt die eingegebene Domain und folgt deren internen Links
- List: Crawlt eine hinterlegte Liste von URLs
- SERP: Hier kann eine Liste aus Meta-Titles und -Descriptions hochgeladen werden, um die Pixelbreite zu bestimmen (Die Funktion gibt es ebenfalls für einzelne URLs unter dem Reiter „SERP Snippet“ im URL Info Fenster unten – Hilfreich für die Title-Optimierung)
List Modus für ToDos jenseits gewöhnlicher Berichte:
Jeder SEO hat schon die Spider Funktion genutzt. Aber in bestimmten Fällen kann der „List Modus“ sehr hilfreich sein. Hier lädt man einfach eine Liste mit URLs hoch, die dann gecrawlt werden. URLs können aus Dateien extrahiert werden, per copy+paste oder manuell eingetragen werden. Oder – und das ist mit Sicherheit die coolste Option überhaupt – sie können über die Funktion „Download Sitemap“ direkt aus der Sitemap einer URL extrahiert werden. Besser gehts ja wohl nicht. Aber eine Sache ist im List Mode nicht möglich. In diesem Modus kann man sich nicht die Inlinks der gecrawlten URLs anzeigen lassen, da der Frosch dafür natürlich die gesamte Domain crawlen muss.
Anwendungsbeispiele:
- Sitemap einer Domain crawlen
- nur die relevantesten Seiten einer Domain crawlen
- URLs mit 404-Response in der Sitemap identifizieren
- Statuscodes von URLs im Bulk checken
- Statuscodes von Backlinks checken (sehr geil um Potenziale aufzudecken, mehr dazu in der Zukunft)
Tipp: XML-Sitemaps mit dem Screaming Frog erstellen
Die Funktion zur Sitemap-Erstellung befindet sich im Hauptmenü unter „Sitemaps„.
Hier lässt sich genau einstellen, ob kanonische, paginierte oder mit noindex ausgezeichnete Seiten aufgenommen werden sollen.
Priorities und modify dates und alles weitere lassen sich ebenfalls festlegen. Kurz: Hier findet man alles, was man braucht.
SERP Modus – Potenziale zur Titleoptimierung aufdecken
Exportiert euch durch Filtern in Excel aus einem Sitemap-Crawlbericht alle Meta-Titles & Meta-Descriptions zu den URLs und schickt diese dann erneut durch den „SERP Modus„. So bekommt ihr auf einen Blick alle relevanten URLs, deren Meta-Snippets zu viele Pixel haben, angezeigt: Ein wunderbarer schneller Überblick, um Potenziale für die Snippetoptimierung zu finden.
5. Mit Custom Filtern gezielt Inhalte & Fehler finden
Wem das hier alles noch nicht fortgeschritten genug war, der sollte sich ein mal mit „Custom Filters“ beschäftigen. Custom Filter durchsuchen den HTML-Quellcode der Seite und müssen deshalb vor dem Crawlen definiert werden. Mit ihnen kann man URLs, die den Filter matchen, ausfindig machen und sogar extrahieren. Die Möglichkeiten damit bestimmte Ziel-URLs eurer Domain zu finden sind damit fast unbegrenzt: Hier kommt es darauf an, wie gut ihr eure Domain kennt. Eine schöne Anwendungsfunktion für Custom Filter ist das Aufspüren von Soft-404 Fehlern (Kurz: Seiten ohne Inhalt, aber mit 200 Statuscode, statt 404er). Voraussetzung ist natürlich, dass ihr diese Seiten anhand eines Codeschnipsels eingrenzen könnt.
Einige konkrete Anwendungsbeispiele:
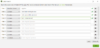
- Filter 1: Finde Seiten mit fehlender schema.org Annotation (hier fehlendes og:price tag)
- Filter 2: Finde Soft 404-Seiten (sofern man weiß, welcher Text auf ihnen ausgegeben wird)
- Filter 3 & 4: Findet Seiten mit einem bestimmten Ankertext und Seiten mit einem bestimmten Linkziel. Aus der Schnittmenge dieser beiden Filterergebnisse könnte man in Excel durch gegenseitigen Ausschluß eine Liste erstellen, in der Potenziale zur internen Verlinkung aufgedeckt werden.
Die Möglickeiten sind unendlich
Bei diesen 5 Tipps sollte eigentlich für jeden Geschmack was dabeigewesen sein. Tatsächlich kann der Crawler aus gutem britischen Hause aber wesentlich mehr als wir hier anmuten lassen: Proxy Crawling, URL-rewriting, Crawling mit accept language im Header, Search Consolen und Analytics API verbinden, Broken Backlink Potenziale analysieren. Etc. E. T. C. Die Einsatzmöglichkeiten für den schreienden Frosch sind schier unbegrenzt. Welche Tipps und Tricks kennst du mit dem Screaming Frog? Sei kein Frosch und schreib es in die Kommentare!
Brauchen Sie Unterstützung bei diesem Thema?
Sprechen Sie uns unverbindlich an und lassen Sie sich von uns beraten.
Crawl-Budget steuern, optimieren und bessere ranken
Eines der wichtigsten Themen für Websites, wenn es um Suchmaschinenoptimierung geht, ist nach wie vor Crawling und Indexierung. Vor allem: Dem Googlebot durch gezielte Steuerung des Crawlings alle Unterseiten und Produkte Ihrer Website zugänglich machen, sodass diese heruntergeladen und in…
So bauen Sie die perfekte Website-Struktur
Eine saubere Website-Struktur ist ein absolutes Muss für den User, ein wichtiger Aspekt für den Crawler und gleichzeitig eine Herausforderung für den komplexen Onlineshop. Besonders bei Shops mit breitem Warensortiment sollte bereits früh geplant werden, wie die Ebenenstruktur der Website…
Klickstarke Meta Tags in 4 Schritten
Sie wollen, dass Ihre Website potenzielle Käufer über die Suchmaschine anlockt? Dann sollten Sie sich darüber Gedanken machen, wie Ihre Website in den Suchergebnissen dasteht. Und zwar nicht nur für welche Suchbegriffe, sondern auch wie die Suchergebnisse aussehen: Regen Sie…


