HTTP-Statuscodes: Verwendung, Tipps & SEO Best Practices
HTTP-Statuscodes: Sie sind ein fester Bestandteil unserer täglichen Nutzung des Internets, dennoch sind uns die meisten eher unbekannt. Während uns die 404 Fehlermeldung beim Browsen durch das Internet öfter begegnet als uns lieb ist, gibt es eine Menge an Status Codes, die uns zwar nicht vertraut sind, für die einfache Nutzung des Internets aber unverzichtbar sind. Doch was genau ist eigentlich ein Status Code? Welche Status Codes gibt es und wofür werden sie jeweils eingesetzt? Neben der Beantwortung dieser Fragen klären wir außerdem über die Rolle der Status-Codes bei der Suchmaschinenoptimierung auf – verständlich auch für Nicht-SEO-Experten.

Was sind HTTP-Statuscodes?
Um zu verstehen, was Statuscodes sind und welche Rolle sie für das World Wide Web spielen, bedarf es ein Grundverständnis davon, wie es überhaupt aufgebaut ist. Das Internet ist ein riesiges Netz aus Clients (Webbrowser, Google Bot) und Servern, die alle verbunden sind und miteinander kommunizieren können. Die Kommunikation erfolgt dabei größtenteils über das Hypertext Transfer Protocol (HTTP), was den Austausch von Dateien zwischen den verschiedenen Parteien überhaupt erst ermöglicht.
Immer, wenn wir eine Webseite aufrufen, sendet der Client (in dem Fall unser Browser) eine Anfrage mittels dieses Protokolls an den Webserver, auf dem die entsprechende Webseite gespeichert ist. Der Webserver gibt dann als Antwort neben der angeforderten Ressource auch einen HTTP-Statuscode als Antwort an den Client zurück, der im Header übertragen wird. Dieser teilt dem Client mit:
- ob die Anfrage erfolgreich war oder nicht,
- ob eine Weiterleitung stattfindet,
- ob ein client- oder serverseitiger Fehler aufgetreten ist.
Diese Mitteilungen sind unter anderem in eindeutigen Statuscodes realisiert. Dabei können diese Status- oder Response Codes sichtbar für den Nutzer sein, wie die 404 Fehlermeldung, die oftmals als Fehlerseite visuell dargestellt wird. Die meisten Statuscodes laufen jedoch ab, ohne dass der Nutzer diese bewusst wahrnimmt. Dies ist zum Beispiel bei 301-Weiterleitungen der Fall.
Damit Seiten von Nutzern über Suchmaschinen überhaupt gefunden werden können, müssen diese durch einen sogenannten Crawler (z. B. Googlebot) erfasst und indexiert werden. Dabei greift dieser Crawler auf Websites zu, wie es ein Browser auch tun würde, indem er mittels HTTP die jeweilige Seite des entsprechenden Webservers aufruft. Neben wichtigen Daten, aus denen die Suchmaschine dann das Ranking der Seite ableitet, erfasst er auch den HTTP-Statuscode der Seite, der ebenfalls eine wichtige Rolle für das Ranking einer Seite spielt. Aus diesem Grund ist es für Websites vor allem hinsichtlich ihrer Auffindbarkeit durch Suchmaschinen wichtig, auf die korrekte Verwendung der Statuscodes zu achten.
Die meisten HTTP-Statuscodes sind sowohl für den normalen Nutzer, als auch für die Suchmaschinenoptimierung von großer Bedeutung. Soll beispielsweise eine Domain im Zuge eines Relaunch zu einer neuen Domain umziehen, ermöglicht die 301-Weiterleitung, dass der Nutzer wie gewohnt die Seiten aufrufen kann und automatisch zu der neuen Domain umgeleitet wird.
Welche HTTP-Statuscodes gibt es?
Die verschiedenen Response Codes können in die fünf Statusklassen informativ, Erfolg, Weiterleitung/ Umleitung, Client-Fehler und Server-Fehler eingeteilt werden. Die erste Ziffer eines Statuscodes gibt an, welcher Klasse der jeweilige Statuscodes zugeordnet werden kann. Jeder Klasse können dabei eine Vielzahl an verschiedenen Statuscodes zugeordnet werden, von denen Sie jedoch den meisten kaum begegnen werden und deren vollständige Auflistung den Umfang des Artikels sprengen würde. Ein Blick in eine Auflistung aller HTTP-Statuscodes kann dennoch sehr interessant sein.
HTTP-Statuscodes können unterschiedliche Funktionen haben. Während einige lediglich informativer Natur sind, weisen andere auf Fehler hin, die bestenfalls behoben werden sollten.
Die wichtigsten Statuscodes im Überblick
2xx Statuscodes: Erfolgreiche Anfragen
200er Statuscodes informieren den Client darüber, dass die Anfrage in irgendeiner Form erfolgreich war. Der Statuscode 200 ist dabei der optimale Response Code, da er signalisiert, dass keine Fehler aufgetreten sind und die Anfrage ohne Einschränkung erfolgreich abgeschlossen wurde. Demnach ist dieser Statuscode auch für SEOs ein wünschenswerter Zustand.
| 200: OK |
| |
| 201: Created |
| |
| 202: Accepted |
|
Das Überprüfen des Statuscodes einer Seite ist ein wichtiger Punkt jedes technischen Checks einer Seite, da hier gravierende Fehler aufgedeckt werden können. Findet man bei diesem Check wie in diesem Beispiel einen 200er Status vor, ist das fast immer ein gutes Zeichen.
BEISPIEL FÜR EINEN 200-STATUSCODE
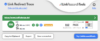
Mit dem Tool Link Redirect Trace, welches man kostenslos als Extension für den Browser herunterladen kann, kann man mit einem Mausklick sowohl den aktuellen Statuscode der Seite, als auch deren Indexierungsstatus und mögliche Canonicals ablesen.
Statuscodes können auch direkt in Google Chrome abgerufen und überprüft werden. Hierzu kann mit F12 die Google Entwicklerkonsole geöffnet werden und mit einem Klick auf „Network“ der jeweilige Statuscode ausgegeben werden.
BEISPIEL FÜR STATUSCODE ABRUF ÜBER DIE GOOGLE ENTWICKLERKONSOLE
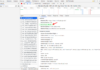
3xx Statuscodes: Weiterleitungen & Co.
Da 300er Statuscodes vor allem für die Suchmaschinenoptimierung eine wichtige Rolle spielen, werden diese im Folgenden etwas detailreicher beschrieben.
Was ist ein Redirect?
Eine Weiterleitung (engl. Redirect) ist ein Prozess, bei dem der Nutzer, der eine bestimmte URL anfragt, zu einer anderen URL umgeleitet wird. Der URI (Uniform Resource Identifier), eine Zeichenfolge zur Identifizierung von Ressourcen im Internet, wird demnach zeitweise oder permanent geändert. Permanente Weiterleitung sind beispielsweise für den Relaunch einer Seite unverzichtbar, während temporäre Weiterleitung für saisonalen Content sehr sinnvoll sein können.
Weiterleitungen können serverseitig- oder clientseitig sein, wobei serverseitige Weiterleitungen oft der Standard sind. Alle Formen von Redirects erfolgen automatisch und werden meistens vom Nutzer gar nicht wahrgenommen.
Die Wahl des zu verwenden Redirects hängt nicht nur davon ab, ob die Seite permanent oder nur temporär weitergeleitet werden soll. Auch die HTTP-Version sowie die verwendete Request-Methode spielen eine wichtige Rolle, geht es darum, welche Weiterleitung im jeweiligen Fall die sinnvollste ist.
Request-Methoden (deutsch: Anfragemethoden) ermöglichen es dem Client, Dateien und Informationen an den Server zu senden. Während die sogenannte GET-Methode lediglich dazu dient, andere Daten als Antwort zu empfangen, ermöglicht die POST-Methode das Verändern von auf dem Server vorhandenen Daten.
Beispielsweise können große Datenmengen wie Bilder zur weiteren Verarbeitung mit der POST-Methode an den Server gesendet werden. Die POST-Methode sollte zwingend verwendet werden, geht es darum, Logindaten wie Passwörter zu übermitteln. Die zu verwendende Request-Methode hängt also von der jeweiligen Anfrage ab.
| 301: Moved Permanently |
| |
| 302: Found / Moved Temporarily |
| |
| 304: Not Modified |
| |
| 307: Temporary Redirect |
| |
| 308: Permanent Redirect |
|
Die in der Tabelle aufgeführten Weiterleitungen sind in ihrer Funktion alle sehr ähnlich und unterscheiden sich teilweise lediglich in technischen Aspekten. Die Weiterleitung, die Sie sich jedoch unbedingt merken sollten, ist die 301-Weiterleitung:
BEISPIEL FÜR EINE 301-WEITERLEITUNG
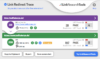
Dieser Screenshot zeigt eine erfolgreich implementierte 301-Weiterleitung von einer veralteten http-Seite zur aktuellen https-Seite. Hier wurde die 301-Weiterleitung verwendet, da die Weiterleitung permanent erfolgen soll. Ein wichtiger Unterschied zu der 302-Weiterleitung, die ähnliche Funktionen wie die 301-Weiterleitung übernimmt, ist das Ersetzen der alten URL durch die neue URL von Google. Bei der 302-Weiterleitung wird die alte URL, aufgrund der lediglich temporären Umleitung, beibehalten.
BEISPIEL FÜR EINE WEITERLEITUNGSKETTE

Wie werden Redirects implementiert?
Redirects können sowohl serverseitig- als auch clientseitig gesetzt werden und werden immer im Header des Dokuments an den Client übermittelt. Dabei kann der Header serverseitig beispielsweise über Programmiersprachen manuell angepasst werden. Möglichkeiten für eine clientseitige Implementierung sind:
- HTML-Meta-Tag: durch das Hinzufügen der Weiterleitung in den <head> einer HTML-Datei kann eine Weiterleitung erfolgen. Hiervon wird jedoch eher abgeraten.
- .htaccess-Datei: besser ist das Schreiben der gewünschten Weiterleitung in die htaccess-Datei der Seite. Hierbei handelt es sich um eine Datei mit Anweisungen für den Server, die dieser bei einer http-Anfrage ausführen soll.
- JavaScript: auch von der Nutzung von JavaScript zur Einrichtung von Weiterleitungen wird eher abgeraten.
Redirects und SEO
Warum ist es überhaupt so wichtig, weiterzuleiten? Die Antwort auf diese Frage ist ganz einfach: einerseits sollen 404 Seiten vermieden werden, welche sowohl für den Nutzer lästig sind, als auch für SEO einen negativen Effekt haben. Zum anderen sollen doppelte Inhalte vermieden werden, welche sich sehr schlecht auf das Ranking einer Seite auswirken können. Existieren eine alte und eine neue Version einer Seite, auf die jedoch nicht weitergeleitet wird, weiß Google nicht, welche Seite indexiert werden soll. Google nimmt dann eine Version der Seite als Duplicate Content wahr, was Google prinzipiell abstraft. Hier können alternativ oder zusätzlich Canocial-Tags eingesetzt werden, um von der Duplikatseite auf die Originalseite zu verweisen.
Einer der aus SEO Sicht wichtigsten Effekte einer Umleitung ist jedoch, dass über die richtige Weiterleitung der mühsam aufgebaute Link-Juice an die andere URL weitergegeben werden kann. Sie sollten sich demnach die Frage stellen: Sollen Link-Juice oder Ranking-Signale über die Weiterleitung weitergeleitet werden? Diese Frage werden Sie vermutlich mit Ja beantworten, vor allem, wenn Sie eine URL permanent zu einer anderen umleiten.
Suchmaschinen betrachten hierfür den verwendeten Statuscode und weitere technische Aspekte und geben dementsprechend Link-Juice und Ranking-Signale weiter oder nicht. Wird eine Weiterleitung gar nicht oder falsch eingerichtet, kann dies fatale Folgen für das Ranking der Seite bedeuten. Alle gesammelten Backlinks, die je nach Qualität und Quantität erheblich zu einem besseren Ranking der Seite beitragen können, gehen verloren und auch das gesamte URL-Rating muss nochmals erarbeitet werden.
4xx Statuscodes: Da ist was schiefgelaufen
Mit 400er Statuscodes, insbesondere mit der 404-Fehlermeldung, haben wir als Nutzer wohl die meisten Berührungspunkte. Sie werden uns angezeigt, wenn der Inhalt der Seite nicht gefunden werden kann.
BEISPIEL FÜR EINE 404-FEHLERSEITE: PIXAR
| 401: Unauthorized |
|
| 403: Forbidden |
|
| 404: Not Found |
|
| 410: Gone |
|
Der 404-Statuscode wird ausgegeben, wenn die gewünschte Seite nicht gefunden wird, und somit nicht ausgegeben werden kann. Dies kann zum Beispiel der Fall sein, wenn ein Produkt in einem Online-Shop nicht mehr verfügbar ist, bzw. nicht mehr angeboten wird.
Dass das Ganze auch interaktiv gestaltet werden kann, zeigt das Neuwagen-Vergleichsportal Carwow mit seiner originellen 404-Seite. Hier wird der User mit einem 2D Rennspiel über die nicht vorhandene Seite hinweg getröstet: https://www.carwow.de/404.
Der 410-Statuscode kommt zum Einsatz, wenn Seiten möglichst schnell aus dem Index von Google verschwinden sollen, weil sie beispielsweise nicht mehr aktuell sind.
Daher wird der Statuscode vor allem bei Seiten mit Inhalten eingesetzt, die nur für eine kurze Zeit aktuell und relevant sind, wie z. B. Veranstaltungs- und Eventseiten. Da die Seiten nach dem Stattfinden der Veranstaltung nicht mehr aufgerufen werden sollen, werden sie mithilfe des 410-Statuscodes schnellstmöglich gelöscht und deindexiert.
5xx Statuscodes: Der Fehler liegt beim Server
500er Fehler begegnen uns glücklicherweise eher selten und weisen darauf hin, dass der Inhalt aufgrund eines serverseitigen Fehlers nicht geladen werden kann.
5xx – Server-Fehler: Statuscodes dieser Klasse verweisen auf Fehler, die auf den Server zurückzuführen sind. Die Anfrage ist temporär oder auch permanent nicht ausführbar.
| 500: Server Error |
|
| 503: Unavailable |
|
500er Fehler treten beispielsweise auf, wenn es ein Problem mit dem genutzten Content-Management-System gibt.
BEISPIEL FÜR EINEN SERVERFEHLER AUFGRUND EINES FEHLERS IM SHOPSYSTEM
Auswirkungen von 500er Fehlern auf SEO
URLs, die einen 500er Fehler aufweisen, sollten bei einem technischen Check stets priorisiert behandelt werden, da der Linkjuice von Seiten mit 500er Status schnell verschwindet. Außerdem gehen nicht nur Nutzer verloren, die auf einer solchen Seite landen, sondern auch der Google Bot, der betroffene Seiten sehr schnell aus dem Ranking schmeißt. Es kann anschließend, anders als bei 400er Fehlerseiten, sehr lange dauern, bis Google die Seiten erneut crawlt und nach einer Fehlerbehebung erneut in den Index aufnimmt.
1xx Statuscodes: Die Informativen
Aufgrund ihrer geringen Relevanz für Nutzer und SEOs werfen wir abschließend nur einen kurzen Blick auf die 100er Statuscodes.
Die 100er Statuscodes liefern wichtige Informationen an den Client. Aus der Sicht des Nutzers, aber auch aus der Sicht der Suchmaschinenoptimierung, sind diese Statuscodes jedoch zu vernachlässigen, da man in der Praxis kaum Berührungspunkte mit diesen Statuscodes hat.
| 100: Continue |
|
| 101: Switching Protokoll |
|
| 102: Processing |
|
Fazit zu den Statuscodes
HTTP Statuscodes sind für die erfolgreiche Kommunikation zwischen Clients und Servern unverzichtbar. Beschäftigt man sich näher mit den technischen Aspekten des Internets, ist ein Grundwissen zu den wichtigsten Statuscodes ein Muss. Insbesondere hinsichtlich der Optimierung von Webseiten für Suchmaschinen wie Google ist der Einsatz der korrekten Status Codes von hoher Wichtigkeit.
Sie haben Fragen oder Anmerkungen zu diesem Artikel oder zum Thema HTTP-Statuscodes allgemein? Lassen Sie es uns in den Kommentaren wissen!
Das HTTP-Statuscode Cheat Sheet
Sie können sich das alles nicht direkt merken und wollen die Informationen für sich speichern? Wir haben alles Wichtige rund um die Statuscodes in einem übersichtlichen PDF zusammengefasst, das für Sie zum Download bereitsteht.
Jetzt das HTTP-Statusscode Cheat Sheet herunterladen
Brauchen Sie Unterstützung bei diesem Thema?
Sprechen Sie uns unverbindlich an und lassen Sie sich von uns beraten.
Crawl-Budget steuern, optimieren und bessere ranken
Eines der wichtigsten Themen für Websites, wenn es um Suchmaschinenoptimierung geht, ist nach wie vor Crawling und Indexierung. Vor allem: Dem Googlebot durch gezielte Steuerung des Crawlings alle Unterseiten und Produkte Ihrer Website zugänglich machen, sodass diese heruntergeladen und in…
So bauen Sie die perfekte Website-Struktur
Eine saubere Website-Struktur ist ein absolutes Muss für den User, ein wichtiger Aspekt für den Crawler und gleichzeitig eine Herausforderung für den komplexen Onlineshop. Besonders bei Shops mit breitem Warensortiment sollte bereits früh geplant werden, wie die Ebenenstruktur der Website…
Klickstarke Meta Tags in 4 Schritten
Sie wollen, dass Ihre Website potenzielle Käufer über die Suchmaschine anlockt? Dann sollten Sie sich darüber Gedanken machen, wie Ihre Website in den Suchergebnissen dasteht. Und zwar nicht nur für welche Suchbegriffe, sondern auch wie die Suchergebnisse aussehen: Regen Sie…


