Google Crawler und Indexierung: Wie Webseiten in die Suche kommen
Jeden Tag googlen viele Millionen Menschen und suchen Informationen – Wie wird das Wetter? Hat das Café auch montags auf? Wie komme ich zum Bahnhof? Lange bevor man auf die Entertaste drückt, hat der Google Crawler eine unfassbare Menge an Informationen von unendlich vielen Webseiten verarbeitet und ist allzeit bereit, diese sortiert in den Suchergebnissen zu präsentieren. Wie der Crawler Seiten findet, verarbeitet und in den Suchindex aufnimmt, erklären wir in diesem Artikel.

In 5 Schritten vom Crawling zum Ranking
Damit Suchende bei Google Antworten auf ihre Fragen bekommen, muss einiges passieren:
- Crawling Queue: Als Erstes müssen sich die neuen Seiten in der Crawling Queue an die Schlange anstellen und warten, bis sie als Nächstes dran sind.
- Crawler: Dann kommt der Crawler und ruft die Seite auf.
- Processing: Danach ist die Seite im Bereich des Processing.
- Der reine HTML Content einer Seite wird hier ausgelesen und die gefundenen Links zu weiteren Seiten werden zurück in die Crawling Queue geschickt, damit sie auch aufgerufen werden können.
- Enthält die Seite auch dynamische Inhalte wie Javascript, muss die Seite in die Render Queue, um sich für das Rendering anzustellen.
- Im Rendering (WRS) werden die dynamischen Inhalte ausgelesen, damit sie auch für die Indexierung berücksichtigt werden können.
- Indexierung: Der HTML Content wird als Erstes indexiert, da dieser Vorgang zügig vonstattengeht und Rendering für die Indexierung grundsätzlich nicht nötig ist. Anschließend werden die gerenderten Javascript Inhalte indexiert. Stichwort: Asynchronous Processing.
- Ranking: Nur für Inhalte, die im Laufe der Indexierung in den Index gelangt sind, ist dann auch das Ranking der Seite möglich, die sich am Anfang in die Crawl Queue gestellt hat.
DER PROZESS VOM CRAWLING BIS ZUM RANKING
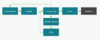
Alle Seiten, die Sie in der Google Suche finden, durchlaufen diesen Prozess. Ohne diesen Prozess gibt es kein Ranking in den Suchergebnissen. Ganz schön aufwendig, oder? Aber so funktioniert die Suche am besten. Wenn man mal überlegt, wie lange man teilweise braucht, um händisch eine sehr gut sortierte Bibliothek nach Informationen zu durchwühlen, ist der komplette Prozess rund um Crawling, Indexierung und Ranking recht beeindruckend. Was genau in den Schritten Crawling, Rendering und Indexierung passiert, damit beschäftigt wir uns jetzt.
1. Crawler und Crawling
Die wichtigste Komponente beim Crawling ist der Crawler. Dabei handelt es sich um ein Programm, das Inhalte im Internet aufrufen und auslesen kann. Der Prozess läuft in der Regel automatisch ab, damit alle Inhalte auch verarbeitet werden können. Diese Crawler werden auch als Bots oder Spider bezeichnet. Google verwendet dabei nicht nur einen einzigen Google-Bot, sondern gleich mehrere Crawler.
Beim Crawling ruft der Google-Bot immer wieder Webseiten auf, die bereits im Index sind sowie URLs, die über die Google Search Console in der XML-Sitemap eingereicht wurden. Dabei folgt der Crawler allen Links. Über interne Links gelangt er auf Unterseiten, über ausgehende Links auf externe Websites. So gelangt er auch auf solche Websites, die noch nicht im Index sind. Ähnlich kommen auch die menschlichen Nutzer über Navigation oder Textlinks von der einen Unterseite oder Website zur nächsten. All diese Seiten warten in der Crawling Queue darauf, wieder aufgerufen zu werden und durch das Folgen der Links stellen sich erneut neue Seiten an.
Laut Google wird „in der Crawling-Software [….] festgelegt, welche Websites wann und wie oft durchsucht und wie viele einzelne Unterseiten von jeder Website aufgerufen werden“. Diese Information kann man als Inhaber einer Website leider nicht einsehen.
Crawling kontrollieren
Webseiten-Inhaber können aber durch unterschiedliche Möglichkeiten festlegen, welche Seiten im Crawling berücksichtigt werden sollen. Die Anzahl der Seiten, die Google im Crawling pro Tag berücksichtigt, ist limitiert. Das sogenannte Crawl-Budget ist dabei nicht festgelegt, sondern abhängig von der Größe einer Seite und der Regelmäßigkeit der Änderung. Durch, zum Beispiel, Parameter URLs, die nicht im Google Index sein sollen, möchte man das Crawl-Budget nicht unnötig ausreizen. Das hilft dabei, dass die wichtigen Seiten einer Webseite auch wirklich im Crawling aufgerufen werden.
Gehen Sie Ihre Seite in Ruhe durch und überlegen Sie sich, welche Inhalte sind relevant und sollen gesehen werden? Haben Sie zum Beispiel Druckversionen Ihrer Seite, dynamisch generierte URLs oder Seiten mit vielen Filteroptionen? Diese sollen Sie vom Crawling-Prozess ausschließen.
Die Umsetzung erfolgt über einen Ausschluss das Crawlers in der robots.txt. So wird dem Crawler von Anfang mitgeteilt, dass er bestimmte Bereiche gar nicht berücksichtigt.
Alle wichtigen Informationen zum Crawl-Budget, dessen Optimierung und wie Sie den Googlebot effektiv durch Ihre Webseite leiten, können Sie in unserem Artikel „SEO für Onlineshops – Teil 6: Crawl-Budget steuern und optimieren“ nachlesen.
2. Processing und Rendering
Crawling allein reicht aber nicht aus, damit eine Seite in den Suchergebnissen zu finden ist. Im Processing wird der reine HTML Content und andere statische Inhalte, wie die CSS Dateien oder Bilder einer Seite verarbeitet und die gefundenen Links zu weiteren Seiten werden zurück in die Crawling Queue geschickt. So kann der Prozess kontinuierlich weiterlaufen. Webseiten können aber auch dynamische Anwendungen wie JavaScript enthalten, welche den Aufbau und das Aussehen der Seite bedeutend ändern können. Der Crawler muss diese Dateien nun extra herunterladen, was einen eigenen Prozess, das Rendering, erfordert.
Warum muss das sein? Für das spätere Ranking sollen alle Inhalte der Seite betrachtet werden. Also alles, was auch NutzerInnen sehen können. Das einfache Crawling kann JavaScript aber nicht erfassen und das Ausführen von JavaScript Dateien erfordert oft eine hohe Rechenleistung. In den Google Richtlinien steht dazu Folgendes:
Alles, was nun als dynamisch erkannt wurde, kann nicht direkt vom Processing zur Indexierung, sondern wird erst mal in die Render Queue gestellt, bis das Rendering stattfindet. Umgesetzt wird es mit einem Web Rendering Service (WRS), der ein üblicher Webbrowser ist. Im Fall von Google ist es die aktuellste Version von Chrome. Das ist besonders wichtig, weil alte Chrome Versionen nicht alle Inhalte so laden können, wie die aktuellen. Durch veraltete Technik sehen die Websites dann anders aus als das, was NutzerInnen auf ihren Geräten sehen können.
Durch die Aufteilung in zwei Schritte kann Google also alle Inhalte lesen, bei den dynamischen Inhalten kann aber gegebenenfalls etwas länger dauern.
Wie das Ganze mit Javascript zusammenhängt und wodurch Probleme in diesem Prozess entstehen können, erklärt Martin Splitt in seiner Youtube-Video Reihe zum Thema Javascript SEO.
3. Indexierung
Bei der Indexierung werden die gefundenen Informationen in einen Index aufgenommen. Es entsteht also eine riesige, digitale Bibliothek. Gibt man nun einen Suchbegriff bei Google ein, greift Google auf seinen Index zurück und spielt die Informationen aus, die zu diesem Suchbegriff passen. NuzterInnen bekommen auf diesem Wege viel schneller verlässlichere Informationen, als wenn Google erst das ganze Internet durchforsten müsste.
Innerhalb eines solchen Indexes werden die Inhalte mithilfe eines Algorithmus sortiert. Sowohl die Befüllung und Verwaltung des Index, also auch die Sortierung wird stetig optimiert. Die Sortierung ist besonders wichtig, da diese beeinflusst, in welcher Reihenfolge die Suchergebnisse bei einer Suchanfrage ausgespielt werden. Sollte die Sortierung nicht gut sein, kann es passieren, dass weniger passende Suchergebnisse auf der ersten Suchergebnisseite auftauchen.
Der nächste Schritt im Prozess ist dann das Ranking, also wie, wann und für welche Suchbegriffe eine Seite angezeigt wird. Wie das passiert und welche Faktoren dabei eine Rolle spielen ist ein ganz eigener Prozess, der an dieser Stelle den Rahmen des Artikels sprengen würde.
Indexierung kontrollieren
Es lässt sich festlegen, welche Inhalte zwar fürs Crawling, aber nicht für die Indexierung berücksichtigt werden sollen. Umsetzen lässt sich das durch die Deindexierung mit Meta-Noindex. Das bietet sich zum Beispiel bei paginierten Seiten an, die durch eine interne Suche entstehen. Diese Seiten listen Inhalte auf, die bereits an anderen Stellen zu finden sind und haben keinen einzigartigen Content. Sie haben keinen besonderen Mehrwert für die Google Suche, beinhalten aber wichtige Links. Durch ein Ausschluss vom Crawling werden diese Links nicht mehr gesehen. Ein Ausschluss von der Indexierung ist hier ratsamer. Über das noindex-Tag teilt man dem Crawler für diese Seite mit, dass sie nicht indexiert werden sollen, der Crawler folgt aber trotzdem den Links und kann so immer noch andere wichtige Inhalte finden. Da die Seiten weiterhin gecrawlt werden, wird hierfür auch Crawl-Budget verwendet.
Was passiert, wenn ich Seiten aktualisiere?
Wenn Sie Seiten überarbeiten und die Änderungen speichern, können Sie und Ihre NutzerInnen natürlich nur die aktualisierte Version sehen. Der Crawler weiß aber noch nicht, dass es etwas Neues gibt. Dafür muss er die Seite erneut crawlen und indexieren. Das passiert zwar automatisch, dauert aber eine gewisse Zeit.
Sie möchten nicht warten, bis der Crawler Ihre Seite erneut aufruft? Sie können dem Crawler auch mitteilen, dass eine Seite möglichst bald neu indexiert werden sollte. Eine detaillierte Anleitung für die neue Search Console, finden Sie in unserem Beitrag „Google findet meine Seite nicht“.
Da das Ranking so eine enge Verknüpfung zum Index hat, ist es natürlich besonders wichtig, dem Crawler Aktualisierungen mitzuteilen. Nur dann können die neuen Inhalte auch berücksichtigt werden und – im Optimalfall – das Ranking positiv beeinflussen.
Und das klappt?
Jein. In vielen Fällen funktioniert die Indexierung reibungslos. Auch nach Seitenupdates sind neue Inhalte dem Crawler zügig bekannt.
Manchmal kommt es aber vor, dass Sie nach Ihrer eigenen Webseite suchen und diese nirgends in den Suchergebnissen angezeigt wird. Grade nach Aktualisierungen ist manchmal Geduld gefragt. Mit unserer bisherigen Erfahrung rechnen wir mit Zeiträumen zwischen 10 Minuten und 3 Tagen nach einer Neubeantragung der Indexierung.
Aber auch Einstellungen wie der Canonical-Tag oder fehlerhafte Meta-Robots-Tags können die Indexierung verhindern. Wir haben für Sie nicht nur sechs typische Fälle von Problemen und Lösungen zusammengestellt, sondern auch 7 Schritte zu einer erfolgreichen SEO-Strategie, sodass Sie erfolgreiches SEO für Ihre indexierte Seite betreiben können.
Brauchen Sie Unterstützung bei diesem Thema?
Sprechen Sie uns unverbindlich an und lassen Sie sich von uns beraten.
Crawl-Budget steuern, optimieren und bessere ranken
Eines der wichtigsten Themen für Websites, wenn es um Suchmaschinenoptimierung geht, ist nach wie vor Crawling und Indexierung. Vor allem: Dem Googlebot durch gezielte Steuerung des Crawlings alle Unterseiten und Produkte Ihrer Website zugänglich machen, sodass diese heruntergeladen und in…
So bauen Sie die perfekte Website-Struktur
Eine saubere Website-Struktur ist ein absolutes Muss für den User, ein wichtiger Aspekt für den Crawler und gleichzeitig eine Herausforderung für den komplexen Onlineshop. Besonders bei Shops mit breitem Warensortiment sollte bereits früh geplant werden, wie die Ebenenstruktur der Website…
Klickstarke Meta Tags in 4 Schritten
Sie wollen, dass Ihre Website potenzielle Käufer über die Suchmaschine anlockt? Dann sollten Sie sich darüber Gedanken machen, wie Ihre Website in den Suchergebnissen dasteht. Und zwar nicht nur für welche Suchbegriffe, sondern auch wie die Suchergebnisse aussehen: Regen Sie…


